Results and Discussion
In this study, three clustering techniques: K-means, Gaussian Mixture Models, and Geostatistical Clustering, were applied to define estimation domains. Figure 5 shows the compelling results obtained.
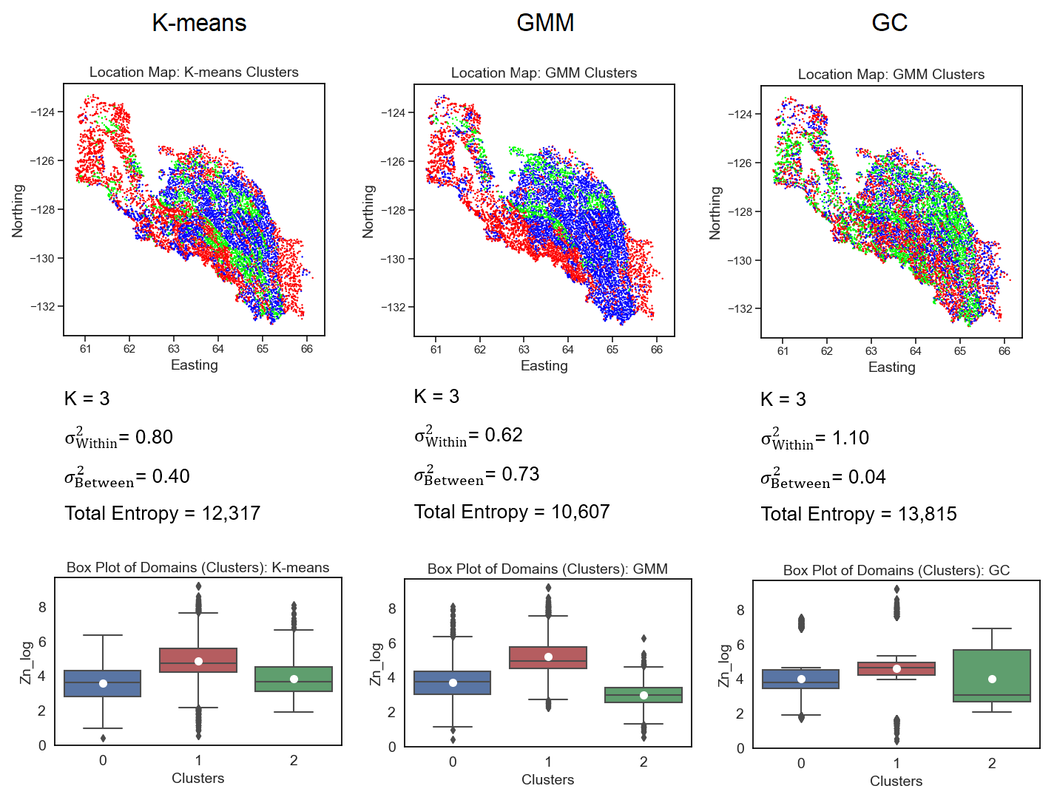
Figure 5: Summary of the results.
The Elbow method effectively identified three clusters as the optimal number. The Gaussian Mixture Model (GMM) performed best among the three methods, with the smallest within-group variance, the highest between-group variance, and the lowest total entropy. The K-means method is followed closely in terms of performance. Interestingly, Geostatistical Clustering (GC), a spatial clustering method, showed the worst performance overall. One possible explanation for the GC's poorer performance could be its focus on a single continuous variable for clustering, specifically Zn_log, which is highly correlated with PC1 and explains 70% of the variance. It may be necessary to modify the method to account for multiple variables to improve its performance.
However, it is important to highlight that the selected metrics effectively represented the quality of the resulting groups. For instance, the entropy metric showed that GMM generates more spatially connected clusters than GC. Furthermore, the within-group and between-group variance effectively captured the variability within the elements of a group and the differences between groups, as demonstrated by the box plots.
However, it is important to highlight that the selected metrics effectively represented the quality of the resulting groups. For instance, the entropy metric showed that GMM generates more spatially connected clusters than GC. Furthermore, the within-group and between-group variance effectively captured the variability within the elements of a group and the differences between groups, as demonstrated by the box plots.
Conclusion
The chosen metrics effectively evaluated the quality of the clusters and distinguished between the best and worst sets of domains. Out of the three methods compared (GMM, K-means, and GC), GMM proved to be the most effective. K-means also performed well, while GC presented relatively poorer results, likely due to its reliance on a single variable for clustering. To improve GC's performance, we suggest modifying the method to incorporate multiple variables.
